2026 — Present
Creator
Verity
Forensic surface comparison as calibrated evidence: transparent likelihood ratios — not black-box 'matches' — from 3-D scans of bullets, cartridge cases, and toolmarks.
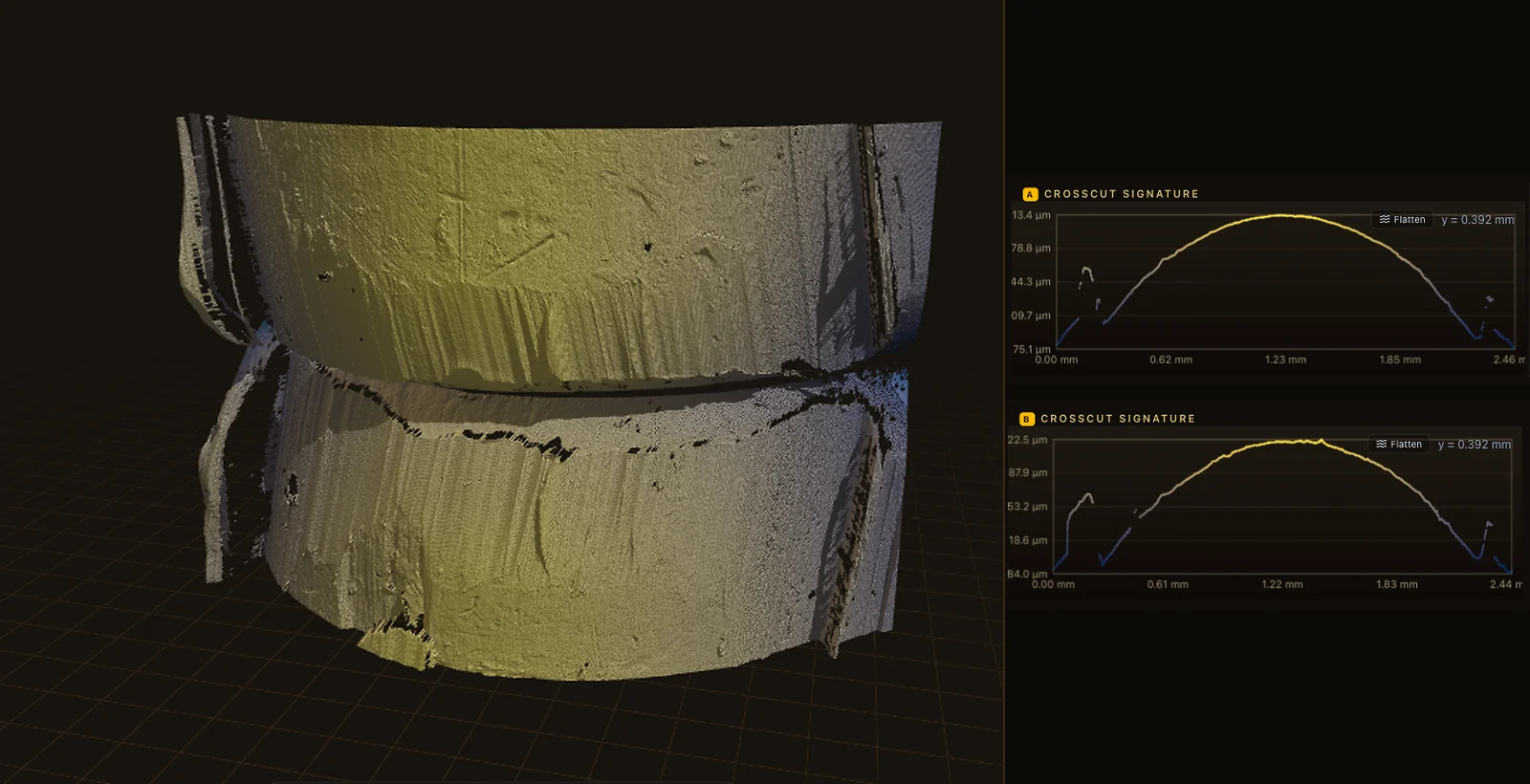
Verity is an open engine for comparing 3-D surface-topography scans — bullet lands,
cartridge-case breech-face impressions, and striated and impressed toolmarks — directly from
X3P (ISO 25178-72) files. It never reports a “match.”
It reports a ComparisonReport: a calibrated likelihood ratio with its verbal equivalent, a
characterized cost (Cllr) on a named reference population, an ELUB bound on how strong a claim
the data can support, and the region-level attribution that drove the score.
It is the direct descendant of my PhD work on bullet matching, rebuilt as a unified, deployable platform instead of a pile of domain-specific R packages.
The method
The comparison layer is Congruent Matching Regions (CMR), a generalization of Song’s Congruent Matching Cells from 2-D cells under translation+rotation to regions of any dimension under any transformation group. One algorithm scores striated marks (where it reduces to Chumbley/CMS), impressed marks (where it reduces exactly to CMC), and — as research — fractured surfaces. The congruent regions double as the attribution map: the explanation is the evidence.
A transparent, ELUB-bounded calibration turns the score into a reportable likelihood ratio, so the report stays interpretable regardless of how the score was computed — the firewall against the black box.
Architecture
A polyglot monorepo: a Rust crate (verity-x3p) is the single source of truth for the X3P
format, with PyO3 and extendr bindings that round-trip files bit-identically across Rust,
Python, and R. On top sit the Python metrology engine (ISO 16610 preprocessing, registration,
CMR, the calibrated-LR decision layer), a FastAPI comparison API, a normalized scan catalog
with content-addressed storage, and the Next.js app at verity.codes —
including an open benchmark leaderboard.
Validation, honestly
Under a barrel-disjoint protocol (no barrel in both train and test), the first-principles scorer reaches AUC ≈ 1.00 and test Cllr ≈ 0.11 on Hamby-252, and Cllr ≈ 0.11–0.35 at AUC ≈ 0.97–1.00 across the four NBTRD bullet studies. The learned representation, trained on 210 scans, does not yet beat the cross-correlation baseline — it overfits, and the repo says so. Nothing in the project claims to know the error rate of forensic examination, which remains unknown.